Open-loop scores measure how well you predict the world; closed-loop scores measure how the world changes once you act in it, and only the second kind keeps you safe.
On evaluating a driving stack
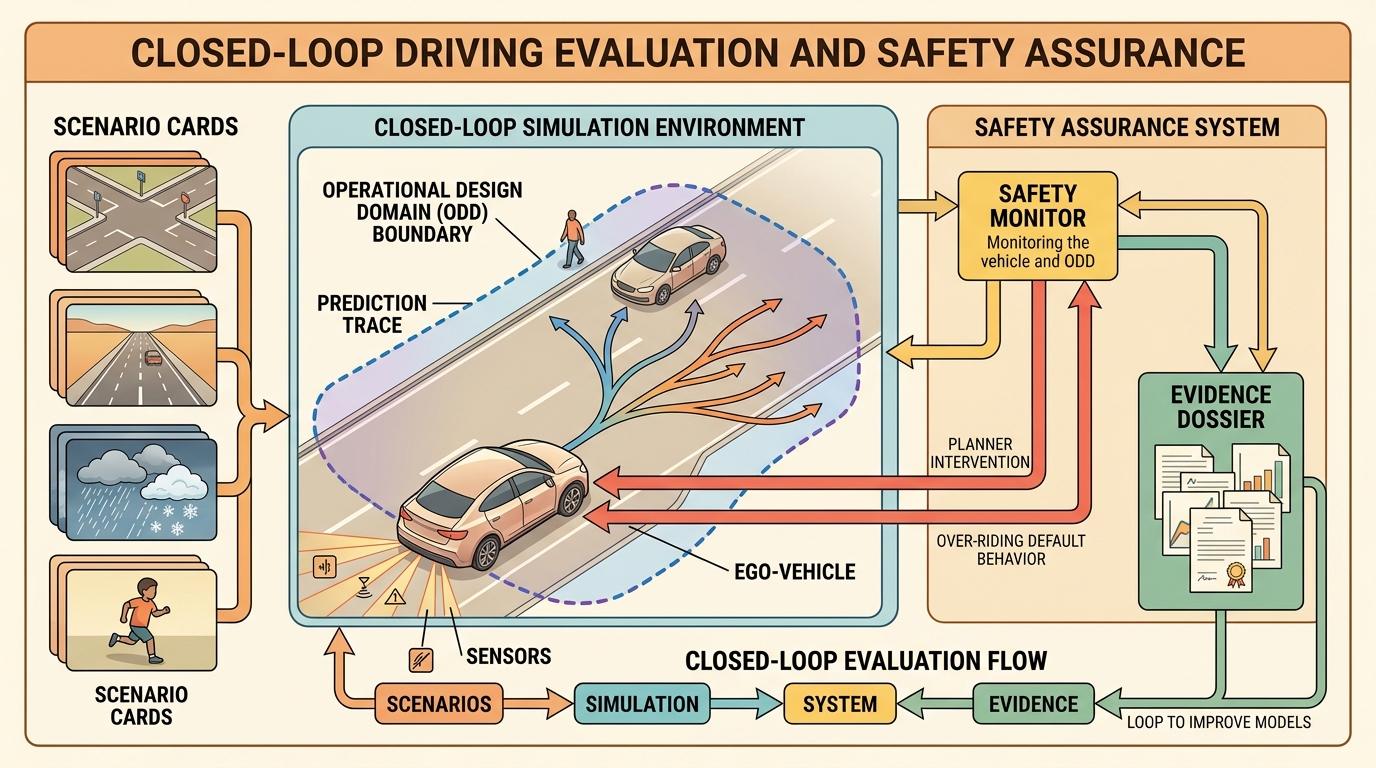
Driving evaluation must distinguish open-loop dataset skill from closed-loop driving behavior. A planner that predicts well can still brake too late, choose the wrong gap, or exploit a benchmark metric while becoming less safe on the road.
Open-Loop Metrics Are Necessary, Not Sufficient
Modern driving stacks are usually evaluated in at least three modes. Open-loop evaluation checks perception or prediction against recorded data. Closed-loop simulation checks how the full stack behaves when its own decisions perturb the future. Safety assurance asks a different question again: which hazards remain, what mitigations exist, and what evidence shows that the mitigations actually work inside the stated operational design domain?
The first two modes are often confused. A forecasting model can improve average displacement error while still making the planner too confident in the wrong interaction pattern. A smoother trajectory generator can reduce jerk while cutting safety margins. A benchmark score can rise even while the vehicle becomes easier to deadlock or easier to surprise in rare conditions.
Once the stack acts, it changes what happens next. That is why route completion, infractions, blocked-agent events, fallback activations, and controller saturation must be part of the evaluation, not mere debugging extras.
Driving Assurance Mathematics
Closed-loop evaluation often reduces the stack to a score, but the useful object is a tuple of behavior and risk:
$$E_{\mathrm{drive}} = (c_{\mathrm{route}}, p_{\mathrm{infractions}}, m_{\mathrm{comfort}}, m_{\mathrm{interaction}}, d_{\mathrm{ODD}}).$$
Here $c_{\mathrm{route}}$ is route completion, $p_{\mathrm{infractions}}$ aggregates collisions and rule violations, $m_{\mathrm{comfort}}$ tracks jerk and acceleration, $m_{\mathrm{interaction}}$ tracks negotiation quality such as deadlock or unsafe gap choice, and $d_{\mathrm{ODD}}$ records how close the scenario lies to the edge of the validated operational design domain.
A useful benchmark formula is therefore not just "higher is better." One representative decomposition is:
$$J_{\mathrm{closed}} = c_{\mathrm{route}} \cdot p_{\mathrm{infractions}}, \qquad \text{subject to } d_{\mathrm{ODD}} \in \mathcal{D}_{\mathrm{validated}}.$$
This captures a core lesson from current leaderboard design: route progress matters, but it is only meaningful when infractions remain low and the scenario still sits inside the claimed ODD. Once the system leaves the validated domain, the benchmark score is no longer a deployment argument, only a research observation.
- Freeze the ODD card: road type, weather, lighting, speed range, traffic density, sensor assumptions, and fallback policy.
- Evaluate perception and prediction open-loop, but keep those metrics tagged as supporting evidence only.
- Run the full stack closed-loop on one scenario panel with one metric script and one taxonomy of infractions.
- Write the strongest defeater for every apparent success: what realistic condition would break this claim?
- Promote only the claims that survive both the metric panel and the defeater review.
Current Toolchain And What It Is For
The practical tool stack for this section is: CARLA Leaderboard, nuPlan, Waymo Open Dataset, Waymo Sim Agents or Waymax, CommonRoad, Autoware, ASAM OpenSCENARIO, OpenDRIVE. Each tool answers a different assurance question. CARLA Leaderboard tests closed-loop route completion with explicit infraction metrics. nuPlan and CommonRoad structure planning evaluation. Waymo's public challenges and simulator tools expose interaction realism. Autoware makes stack interfaces concrete. OpenSCENARIO and OpenDRIVE keep the scenario and map assumptions portable.
| Evidence layer | What to specify | What to save |
|---|---|---|
| ODD | Road type, weather, lighting, speed range, traffic density, map quality, fallback policy. | ODD card with explicit exclusions. |
| Scenario panel | Functional hazards, logical parameter ranges, concrete seeds, and actor scripts. | Scenario manifest plus reproducible seeds. |
| Closed-loop metrics | Route completion, infractions, comfort, blocked-agent events, planner timeouts, controller interventions. | One construct-matched metric artifact. |
| Safety case | Hazards, mitigations, assumptions, and strongest defeaters. | Annotated argument and failure traces. |
| Decision | Deploy, limit, or deny by ODD slice. | Written promotion decision with supporting evidence. |
Stress the system with interaction deadlock, occlusion, map error, braking-distance miscalibration, planner-induced near misses, metric gaming, ODD creep, sensor degradation, and stale fallback assumptions. These are not decorative stressors. They are the ordinary ways an AV stack becomes dangerous while still looking competent on a dashboard.
An AV stack may improve open-loop trajectory forecasting on a merge benchmark, then perform worse closed-loop because the planner trusts the forecast too much and enters gaps that humans would reject. The fix may live in uncertainty calibration, behavior planning, or fallback design rather than in the predictor's average error alone.
Code And Evidence
We can put this into practice with a tiny assurance record. The goal is not to compress the whole safety case into one object. The goal is to force the stack to admit which metric improved, which infraction still happened, and whether the claim is actually promotable.
# Store one closed-loop assurance summary for a driving stack.
# Keep the route metric, infraction metric, and deployment decision together.
from dataclasses import dataclass, asdict
@dataclass
class AssuranceRecord:
scenario_family: str
route_completion_pct: float
infraction_penalty: float
blocked_events: int
strongest_defeater: str
decision: str
def as_row(self) -> dict[str, object]:
return asdict(self)
record = AssuranceRecord(
scenario_family="unprotected_left_turn",
route_completion_pct=96.0,
infraction_penalty=0.91,
blocked_events=1,
strongest_defeater="late response to fast oncoming motorcycle in glare",
decision="limit_to_daylight_until_glare_panel_passes",
)
print(record.as_row())Expected output: the printed record should contain both performance and denial information, not just a success metric. If your assurance artifact cannot name the strongest remaining defeater and the resulting deployment limit, it is a benchmark summary rather than a safety argument.
Use CARLA Leaderboard for closed-loop route and infraction metrics, nuPlan and CommonRoad for structured planning evaluation, Waymo Sim Agents or Waymax for interaction realism studies, and Autoware to make the stack boundaries concrete. The shortcut is valuable because these tools expose public interfaces and public metrics, not because they make the safety problem disappear.
Recipe For Builders
- Write the ODD card before comparing models. A model that works in daylight urban traffic is not automatically a model for glare, heavy rain, rural roads, or emergency-vehicle interactions.
- Use open-loop perception and prediction metrics as supporting evidence, then rerun the exact claim in closed-loop simulation.
- Keep route completion, infractions, comfort, blocked-agent events, and intervention logs in one artifact.
- Write the strongest defeater for every apparent success and convert it into a scenario or an explicit deployment limit.
- Only promote the stack where the metrics and the written safety argument agree.
A strong driving stack is not the one with no scary examples in the slide deck. It is the one whose scary examples have already been turned into explicit defeaters, limits, and regression tests.
Can you explain why a planner with better open-loop prediction metrics might still deserve a narrower ODD after closed-loop evaluation?
The frontier in autonomous driving is shifting from isolated module wins toward world-model simulation, interaction-realistic agent generation, and explicit assurance arguments. The open problem is how to connect those richer models to safety cases without letting generative realism hide unvalidated assumptions.
Closed-Loop Driving Evaluation And Safety Assurance belongs in the book because it teaches the difference between a good score and a defensible driving claim. In embodied AI, that difference is the whole game.
Take one scenario family, compute prediction metrics and closed-loop outcomes on the same panel, then write the safety argument and the strongest remaining defeater. End with a deployment decision that is narrower than the full ODD unless the evidence really supports the full claim.
Section References
CARLA Autonomous Driving Leaderboard. https://leaderboard.carla.org/
Current closed-loop benchmark with explicit route-completion and infraction metrics, including the 2.1 scoring update.
Waymo Open Dataset challenges. https://waymo.com/open/challenges/
Official 2026 note that leaderboards remain active even when formal challenge cycles pause, useful for current benchmark positioning.
Waymo Sim Agents challenge. https://waymo.com/research/the-waymo-open-sim-agents-challenge/
Public reference for interaction-realistic simulation metrics in autonomous driving.
Waymax. https://waymo.com/research/waymax/
Waymo's accelerated simulator for behavior research on motion-dataset scenarios.
Autoware documentation. https://autowarefoundation.github.io/autoware-documentation/main/home/
Open-source driving-stack documentation from sensing through control and simulation.
ISO 21448, Safety of the Intended Functionality. https://www.iso.org/standard/77490.html
Reference standard for reasoning about unsafe behavior without a component failure.
UL 4600 overview. https://users.ece.cmu.edu/~koopman/ul4600/index.html
Accessible overview of an assurance-oriented safety standard for autonomy.