"Every action representation is a promise about what kinds of motion your policy can even imagine."
A Motion-Interface Designer
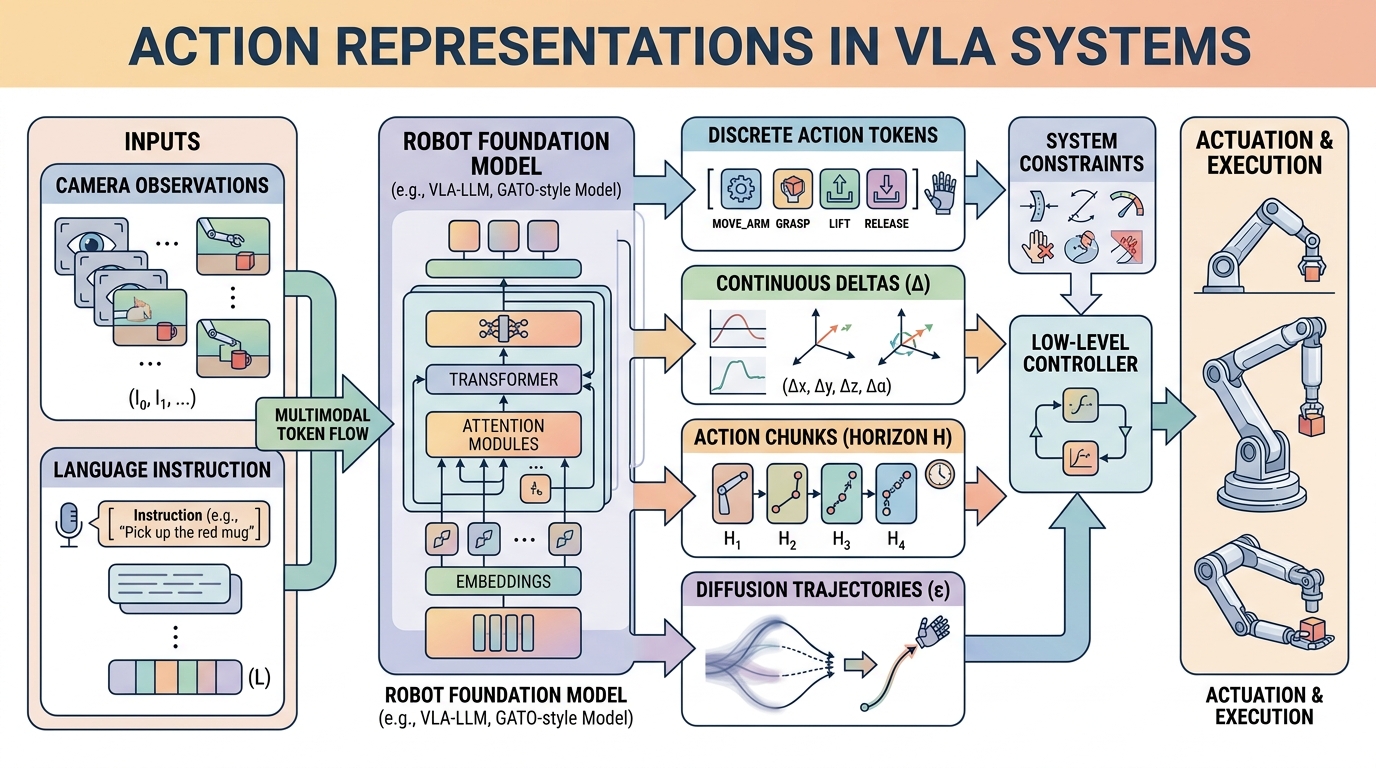
Action representation decides what a VLA can express before learning even starts. Discrete tokens are compact and work naturally with autoregressive decoding. Continuous chunks preserve geometric fidelity. Diffusion and flow heads preserve multi-modality, while hierarchical skills trade low-level expressivity for longer-horizon structure.
The Design Question
An action head has to compress a continuous physical process into a model-friendly interface. The main trade-off is between compact discrete structure and faithful motor detail. If you discretize too aggressively, small but important control variations vanish. If you stay fully continuous, inference can become slower or harder to align with autoregressive backbones.
The field currently uses four broad strategies: per-step discrete tokens, compressed action tokens such as FAST and FAST+, direct continuous chunks, and generative continuous heads such as diffusion or flow matching. The right answer depends on control rate, action smoothness, and how multi-modal the task is.
Token models usually fail through aliasing and sequence length. Continuous heads usually fail through latency, calibration sensitivity, or weaker integration with language-model-style decoders.
A Compact Comparison Formula
A practical comparison uses both fidelity and runtime:
$$J = \alpha \cdot \text{task\_success} - \beta \cdot \text{latency} - \gamma \cdot \text{reconstruction\_error}.$$
The coefficients depend on the application. A dexterous high-rate hand may tolerate more model complexity to reduce reconstruction error. A mobile manipulator with strict runtime bounds may prefer a simpler but faster interface.
Code Fragment 1 contrasts a naive token budget with a chunked representation.
# Compare how many model outputs are needed for the same 1-second control horizon.
control_hz = 20
horizon_s = 1.0
timesteps = int(control_hz * horizon_s)
naive_tokens_per_step = 7
chunk_length = 5
chunk_outputs = timesteps // chunk_length
print(f"naive_token_predictions={timesteps * naive_tokens_per_step}")
print(f"chunk_predictions={chunk_outputs}")
naive_token_predictions=140 chunk_predictions=4
OpenVLA, openpi, and LeRobot toolchains let you swap among discrete-token, chunked, and continuous policy heads without rebuilding the entire training stack. That maintained abstraction matters once the action-interface trade-offs are understood well enough to choose a head deliberately.
When Each Representation Wins
| Representation | Best when | Main risk |
|---|---|---|
| Naive discrete tokens | Low-rate commands or simple proof-of-concept setups | Long sequences and quantization error |
| FAST or FAST+ tokens | Smooth high-rate actions with autoregressive backbones | Tokenizer mismatch across embodiments |
| Continuous chunks | Short-horizon manipulation with explicit controllers | Chunk boundaries can hide mid-course correction needs |
| Diffusion or flow heads | Multi-modal continuous trajectories and dexterous behaviors | Sampling cost and runtime complexity |
| Hierarchical skills | Long-horizon tasks with reusable motion motifs | Low-level nuance may be hidden behind the skill interface |
Diffusion and flow heads are not automatically superior. If your robot runs at low frequency with nearly deterministic action choices, a simpler chunked or tokenized interface may be easier to deploy and debug.
A household mobile manipulator opening a drawer may benefit from chunked continuous actions because the lower-level controller can smooth short-horizon motion. A bimanual dexterous hand manipulating cables may need a richer generative head or a stronger tokenizer because tiny trajectory details matter far more.
Choosing an action representation is like choosing whether to speak to the robot in syllables, full sentences, or dance notation. Every choice drops something and gains something.
Your robot runs at 50 Hz and needs smooth wrist motion. Which representation class would you rule out first, and why would its failure show up as a runtime or reconstruction problem?
FAST and FAST+ strengthened the discrete route by showing that action tokenization can respect smooth continuous trajectories, while pi-zero style flow models strengthened the continuous route. A likely durable outcome is not one winner but a modular interface layer that lets the same VLA backbone swap action heads by task and embodiment.
Action representation is not a small implementation detail. It is the part of the VLA that decides how motor intelligence is packaged, how latency accumulates, and which classes of motion error become likely.
For one robot task of your choice, compare a tokenized and a continuous action interface on the same control horizon. Write down the expected latency, reconstruction risk, and controller burden for each before you run anything.
What's Next?
Chapter 35 broadens this action-interface discussion into full robot foundation models and cross-embodiment learning, where the action contract has to survive changes in robot body, sensor tree, and adaptation workflow.
Section References
Pertsch et al. (2025). "FAST: Efficient Action Tokenization for Vision-Language-Action Models."
The central reference for compression-based action tokenization and the FAST+ tokenizer.
Physical Intelligence. "openpi" repository.
Useful for seeing how pi-zero family models package flow-based and token-based action interfaces in open code.
An open reference for autoregressive VLA training and adaptation workflows.
Useful for practical policy heads, datasets, and evaluation flows on accessible hardware.