"Cross-embodiment robot policies are useful only when the dataset mixture and action conventions are visible."
A Grounded AI Agent
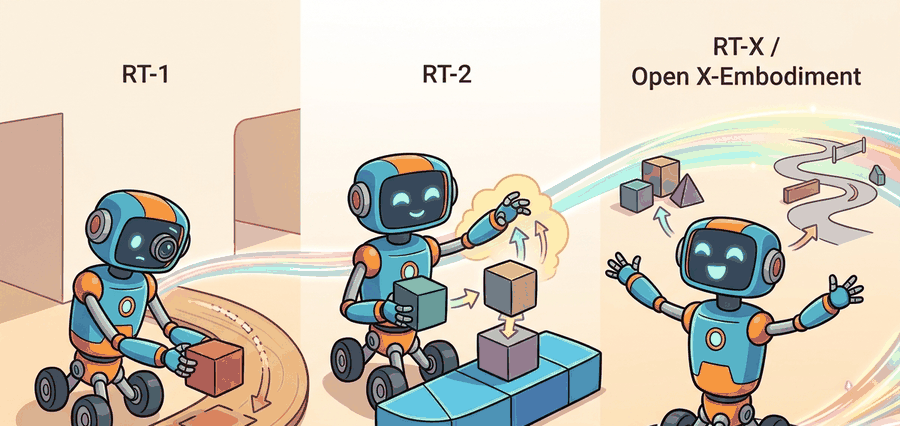
Figure 34.2 should be read as a lineage map from single-robot imitation to web-augmented and multi-robot training. The check is whether each dataset contributes compatible observations, actions, and task labels.
Build And Evaluation Checklist
Curriculum, depth, and self-containment. RT-1, RT-2, and RT-X show the progression from large real-robot transformer policies to action-token VLM fine-tuning and cross-embodiment data mixtures. For The lineage: RT-1, RT-2, RT-X / Open X-Embodiment, the practical reading is to pin down the interface, assumptions, concrete example, and failure mode before comparing methods.
Production and evaluation contract. Compare lineage models only with the same robot, task panel, split, and metric artifact. For The lineage: RT-1, RT-2, RT-X / Open X-Embodiment, treat the diagram, code, table, exercise, warning, and references as one evidence packet: boundary, artifact, tool choice, transfer check, failure mode, and source grounding.
Before accepting a The lineage: RT-1, RT-2, RT-X / Open X-Embodiment result, name the loop variable that changed, the tool that makes it reproducible, the failure that would fool the metric, and the source that backs the claim.
Write an evidence row for a lineage comparison: source dataset, robot embodiment, action convention, evaluation task, held-out condition, and the reason the result is comparable.
# Inspect the fields expected by a VLA dataset before training.
required_fields = ["observation.image", "observation.state", "action", "language_instruction"]
def validate_vla_contract(fields: list[str]) -> str:
missing_prefix = [field for field in fields if "." not in field and field != "action" and field != "language_instruction"]
assert not missing_prefix
return ", ".join(fields)
print("VLA dataset contract:", validate_vla_contract(required_fields))Use LeRobot or an OpenVLA-style repository before writing a custom robot dataset loader. The maintained stack handles episode schemas, image loading, action normalization, and train-eval splits that otherwise take hundreds of lines to rebuild.
This lineage matters because each system moved one boundary: RT-1 scaled robot demonstrations, RT-2 injected web-scale semantics, and RT-X tested whether embodiment-diverse mixtures could produce reusable robot priors.
From One Robot Fleet To Cross-Embodiment Data
RT-1 showed that a transformer policy could learn many manipulation tasks from a large collection of real robot demonstrations. Its important design choice was not only scale. It represented low-level robot actions as discrete tokens, which let the model use sequence modeling machinery for physical control.
RT-2 moved the idea closer to a VLA foundation model. It used Internet-scale vision-language backbones and co-trained them so that robot actions could be emitted as token sequences. This made web knowledge useful for some semantic generalization, such as recognizing objects or interpreting instructions, while still depending on robot data for physical grounding.
RT-1 scaled robot demonstrations, RT-2 fused web semantics with robot actions, and RT-X asked whether pooled data from many embodiments could improve transfer across robots.
What RT-X Changed
Open X-Embodiment made the dataset question impossible to ignore. Instead of treating every robot as a separate island, it standardized data from many institutions and trained RT-X variants across a shared mixture. The result was not universal robot intelligence. The result was a clear empirical lesson: carefully pooled robot data can produce positive transfer when the action and observation interfaces are normalized enough to learn from.
Cross-embodiment learning needs a common language for action. A 7-dimensional end-effector command can represent position, orientation, and gripper state for one arm, but missing dimensions, different control rates, and different grippers must be handled explicitly. Otherwise the model sees a data mixture whose symbols do not mean the same thing.
The lineage also exposes an evaluation trap. If RT-X improves one robot because another robot contributed useful examples, the comparison must be co-computed on the same task family and split. A table that mixes results from different robots, different seeds, or different episode filters can look stronger than the evidence supports.
Suppose a lab adds a new gripper to an Open X-style mixture. The first engineering step is not model training. It is metadata alignment: camera calibration, action scale, control frequency, gripper convention, language labels, and train-test splits. The model can only generalize across embodiments if the data tells it what each embodiment means.
What To Remember For Modern VLAs
Modern systems such as Octo, OpenVLA, SmolVLA, pi-zero, GR00T, and Gemini Robotics all inherit the lineage question: how much of the policy comes from robot data, how much comes from web-scale perception and language, and how much comes from the chosen action head? RT-1, RT-2, and RT-X are not historical footnotes. They define the axes that current systems still vary.
A model can know the word "spatula" from the web and still fail to slide a real spatula under a pancake. Web pretraining helps with semantics, but contact, friction, reachability, compliance, and recovery still come from embodied data and control design.
Read the lineage as a sequence of interface decisions: what changed in the data mixture, what changed in the action head, and what changed in transfer across robots.
Explain the difference between RT-1, RT-2, and RT-X without using the word "bigger." Your answer should mention robot demonstrations, web knowledge, and cross-embodiment data.
The open question is not whether more robot data helps. It does. The harder question is which data should be mixed, how it should be weighted, and when a heterogeneous mixture hurts a target robot by teaching incompatible habits.
The RT lineage teaches the central VLA tradeoff: semantic generalization wants broad pretraining, while motor reliability wants clean, embodiment-aware robot data.
Design a cross-embodiment data table for two robot arms with different grippers. Include fields for action dimension, control rate, camera views, gripper convention, and missing dimensions.
What's Next?
Section 34.3 turns from the Google lineage to open generalist policies that readers can inspect and adapt.
Brohan et al. (2022). "RT-1: Robotics Transformer for Real-World Control at Scale." arXiv.
RT-1 showed that a transformer policy trained on large real robot data could produce discretized low-level robot actions from images and instructions. It is the starting point for the chapter lineage and useful for readers who want the engineering details behind large-scale robot data collection.
RT-2 made the action-as-language move explicit by fine-tuning VLM backbones to emit robot actions as tokens. Researchers should read it for the co-training setup, while practitioners should read it for the limits of transferring web semantics into motor control.
This paper introduced the cross-institution robot data mixture and RT-X models. It is essential for understanding why embodiment metadata, action normalization, and dataset mixture design matter.
Octo Model Team et al. (2024). "Octo: An Open-Source Generalist Robot Policy." arXiv.
Octo is a transformer-based diffusion policy pretrained on Open X-Embodiment trajectories and designed for flexible fine-tuning. It is the clearest open reference for generalist policy initialization before the Internet-pretrained VLA wave.
Kim et al. (2024). "OpenVLA: An Open-Source Vision-Language-Action Model." arXiv.
OpenVLA connects open VLM backbones to robot action generation and provides a practical codebase for fine-tuning. Practitioners should read it alongside the GitHub repository before adapting an open VLA to a new robot.
Hugging Face. "LeRobot." GitHub.
LeRobot is the practical open-source toolkit used here for datasets, policy training, evaluation, and low-cost robot workflows. Engineers should start here before writing custom data loaders or training loops.